こんにちは。grooves エンジニアの福井(@bary822)です。
今回は弊社サービスの一つ、Crowd Agent のサーバーOSをAmazon Linux 2に移行した時の具体的な手順、および特に注意すべき点をご紹介したいと思います。
やらないとな〜と思いつつ時間が取れていなかったり、調査が面倒で実践できていない人の参考になれば嬉しいです。
そもそも、なぜやるのか
オリジナルのAmazon Linux(正式名称: Amazon Linux AMI)は2020年いっぱいをもって既にEOLとなっています。これを使い続けることで以下の問題が発生します。
- libgcc、opensslなど基幹パッケージに対する互換性が保証されたアップデートが提供されない(※重大なセキュリティアップデートなどは除く)
- EC2の新しいインスタンスタイプや新機能の提供はAmazon Linux 2限定となる場合があり、機会損失が発生する
- Amazon Linux 2で大幅に改善されたパフォーマンスによるメリットを享受できない
この記事を書いている時点においてAmazon Linux AMIはmaintenance supportという位置づけで限定的なサポートが提供されていますが、それも2023年6月いっぱいをもって終了となってしまいます。
早かれ遅かれいずれ対応する必要があるのであれば、少しでも早いうちにやっておいてパフォーマンス改善等のメリットを享受するのが得策です。
一方で、今後EC2ベースの構成から例えばECSを使ったコンテナベースの構成に作り変える計画がある場合などは無理に対応する必要はないかと思います。プロダクトの中長期的な計画と照らし合わせながらこのあたりの意思決定を行っていくと良さそうです。
移行手順
おおまかな移行の流れは (1) 変更が必要な点を洗い出す (2) 動作確認 (3) 置き換え作業 となります。ここから詳しく説明していきます。
変更が必要な点を洗い出す
主要な変更点は既にAWSから提供されているFAQページから知ることが出来ます。
いくつかのパッケージが非推奨になっていたり、別途インストールが必要になったりしますが、最も大きなものは伝統的なSystem V系のinit(ブート時のプロセス起動プログラム)の廃止でしょう。これによりUpstarなどを使っていた場合はSystemdへの乗り換えが必須となります。Systemdはいくつかのサービスに分かれて構成されており、そのそれぞれに設定項目が細かく存在するため若干学習コストは高めですが、一度理解するとそれほど難しいものではありません。
また、プロセス監視とリカバリ用途にmonitなどを使っている場合はこの機能もSystemdに移行してしまうのが良いと思います。ほとんどすべての機能はSystemdで代替できるはずです。
とはいえ、すべての必要な変更をドキュメントベースで洗い出すのは困難です。 自動化されたサーバープロビジョニングが可能な状態にあれば、Amazon Linux 2ベースのAMIを使ってまっさらなEC2インスタンスを作成し、既存のプロビジョニングスクリプトを走らせてみるのが良いでしょう。
幸い、Crowd Agentの場合はAnsible PlaybookとPackerによってベースAMIからプロビジョニングスクリプトを流したカスタムAMIを作成する手順が全て自動化されている環境にありましたので、これを何度か試して追加で必要な変更点を洗い出しました。具体的には以下の2つでした。
- pipがデフォルトでインストールされていないので手動でインストールする手順を追加
- NGINXをamazon-linux-extrasからインストールするように変更
これらの工程を経て、無事Amazon Linux 2ベースのAMIにPlaybookが通るようになりました。
動作確認
作成したAmazon Linux 2ベースのカスタムAMIからEC2インスタンスを立ち上げ、アプリケーションをデプロイして動作確認を行います。そもそもデプロイスクリプトが通らない可能性もあるので、動作ログを慎重に確認します。
無事検証用環境(ステージング)にデプロイされたことを確認し、主要機能をブラウザ経由で手動テストしました。
置き換え作業
本番環境では移行期間を設けてより慎重に行います。既存EC2インスタンスと新しいAmazon Linux 2ベースのEC2インスタンスを一定期間共存させて、問題がないことを確認します。
Crowd Agentでは既にALBの後ろにAZの異なる2台のEC2インスタンスを接続していましたので、ここに3つ目のインスタンスとして登録し、同じ割合でリクエストが流入するように設定しました。
アラートやエラーログを確認しつつ1週間ほど様子見し、問題が無さそうだったのでTerraformでコード化された構成も新しいAMIを使ったものに置き換えました。
置き換える際には注意が必要です。当然ですが一度に全てのインスタンスを置き換えるとインスタンス起動中にダウンタイムが発生してしまします。一台ずつ慎重に置き換えを行いましょう。
この時点で古いインスタンスと新しいインスタンスが完全に置き換わりました。めでたしめでたし。
おまけ
Socket Activation
Systemdには Socket Activation という機能が備わっています。これを活用すると、 Pumaプロセスの管理にまつわる頭痛がかなり解消されます。
PumaにはPhased Restartと呼ばれる機能があります。これはダウンタイムを発生させずにPumaプロセスを安全に再起動するための仕組みです。
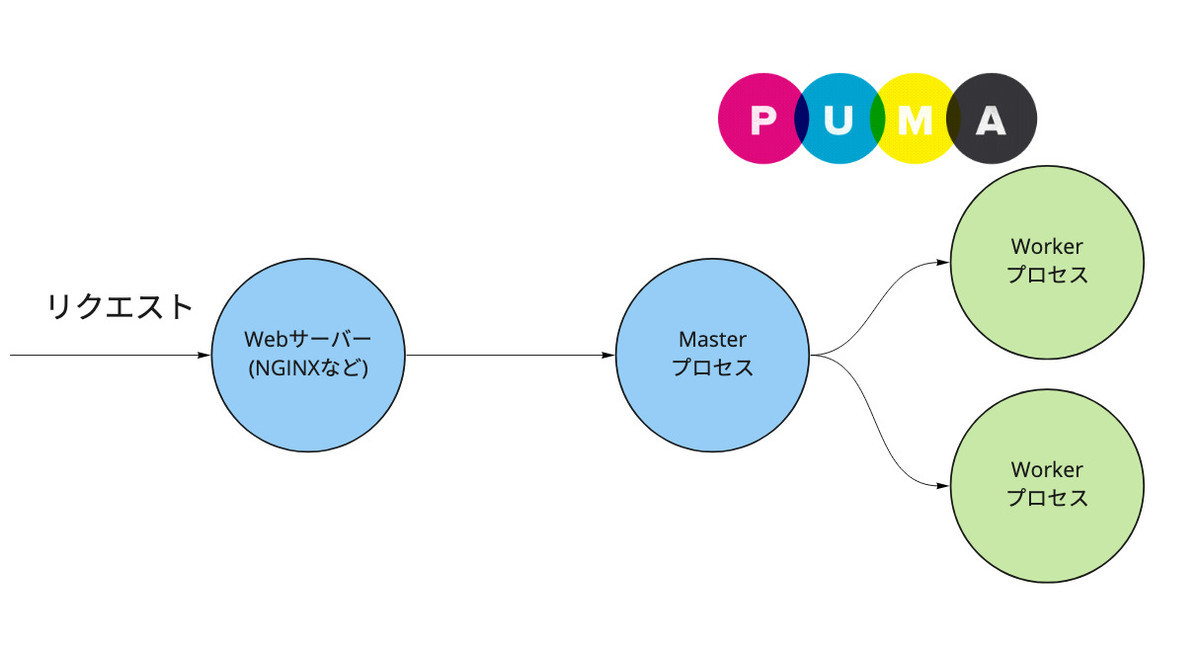
Webサーバーはリクエストを一度PumaのMasterプロセスに流し、そこから実際にRailsの処理が行われるWorkerプロセスに流されます。
Phased Restart中はMasterプロセスでリクエストをキャッシュし、Workerが立ち上がった時点で再びリクエストを流し初めます。これによりダウンタイムを発生させること無く新しいバージョンのRailsアプリを使うことができるようになります。
しかし、これは運用上やっかいな問題を生みます。Phased RestartはMasterプロセスを再起動させることが無いため、例えばPuma gemのバージョンが上がった時はMasterプロセスを手動で再起動させなければなりません。ALBの背後でEC2インスタンスを稼働させている場合は、(1) EC2インスタンス1台をALBからdetach (2) Puma Masterプロセスを手動で再起動 (3) ALBに再びattach というめんどくさい手順を取る必要があります。
Socket Activationすればこの問題を解決できます。
これまでWebサーバーがリクエストを流していたsocketファイルはPuma Masterプロセスによって作成されたものでしたが、これをSystemdによって作成されたものに置き換えます。これにより再起動中などでPumaプロセスがリクエストを受け付けられない時はSystemdがキープ(キャッシュ)してくれるようになります。つまり、新しいバージョンをデプロイするタイミングでMasterプロセスごと気軽に再起動できるようになるのです。
Puma側の設定はとてもシンプルで、bind_to_activated_socketsというオプションを有効化するだけです。
ref: https://github.com/puma/puma/blob/v5.5.2/docs/systemd.md#binding
Gemのバージョンアップごとに手動での作業が必要となるとそれだけで腰が重くなり、結果的に最新バージョンから遅れをとることも多いかと思うので、これはぜひ有効化することをおすすめします。