こんにちは。grooves エンジニアの福井(@bary822)です。今日はインフラ負債の解消についてお話したいと思います。
プロダクトがローンチしたばかりの頃はとにかく新機能開発を優先することがほとんどかと思いますが、ユーザー数がそれなりに増えて障害発生時の影響が大きくなると信頼性を担保することも重要になってきます。
しかし、これまで機能開発をメインに行なってきた開発者にいきなり「信頼性だ!」と言っても何をしてよいかわからないこともあるでしょう。
信頼性を向上させるための施策は主にインフラレイヤーで行われることが多いですが、groovesはいわゆる「Railsフルスタック」のエンジニアを中心に採用してきた経緯があり、インフラは初期構成から大きく改善されないまま数年が経過していました。この間、AWSなどのインフラ系クラウドサービスには新サービスが続々と誕生したり、様々なサポートが追加されたりしてそれを活かさないだけで機会損失が発生してしまうという状態が継続していました。
この課題はgroovesが開発する Crowd Agent, Forkwell という2つのサービスで共通して存在するものであり、それぞれを個別のチームで解決するというよりは画一のソリューションを両者に適用していったほうが効率が良さそうに思えました。
そこで私はこれまで溜まったインフラ負債の解消と、これから負債が溜まらないように体制を確立することを目的とした専門組織「クラウド推進室」の立ち上げを行うことにしました。
このエントリーでは実際に立ち上げの際に行ったことやこれまでの施策とその成果についてお話します。同じような課題を抱えているけど、どうやって解決していったらよいか悩んでいる方に向けて解決のヒントとなれば嬉しいです。
課題スコープの定義
一番最初に行ったのは数多く存在するインフラにまつわる課題の中で、新しく立ち上げるチームが解決すべきものを抽出することでした。大量の課題を見境なく全て解決しようとすると本当に解決すべき課題にフォーカスできなかったり、解決する価値があまりない課題に大量のリソースを投下してしまう恐れがあります。
当初、溜まったインフラ負債によって「モダンなインフラ」では発生しないような運用コストがかかっていることや、不十分な監視基盤によって障害対応に時間がかかってしまう、現状を正しく把握できないと言った問題を課題スコープの中心と据えることを考えました。しかし、ここで踏みとどまります。
理由は、現状の課題を解決するだけではまた新たな負債が溜まり同じことを繰り返すと思ったからです。それよりも日々の開発の中で適切にインフラを新しくしたり、新機能の設計段階から適切なインフラ構成を行えるようし、持続可能な形でインフラ負債が溜まらないようにする仕組みを構築すべきだと考えなおしました。
そこで大方針として解決する課題のスコープを (1) インフラ負債の解消 (2) インフラ負債が溜まってしまう体制の改善 とすることにしました。具体的には以下の4つです。
- 不十分でレガシーなインフラ構成、監視基盤による弊害 - (1)
- ナレッジの分散 - (2)
- インフラスキルの偏在、属人化 - (2)
- インフラ領域への投資妥当性判断を行いづらい - (2)
まずは旧式のインフラ構成によって不必要なメンテナンスコストがかかっている問題や、十分な監視が行えず信頼性が担保しづらい、デバッグに時間がかかってしまっている問題を解決します。
また、各サービスでこれまで培われてきたノウハウや業界のベストプラクティスなどの知識を集結し、それを開発者全員に教育することで日頃の開発活動の一環としてインフラのアップデートを行える状態にする。また、そのための工数を合理的に捻出するためにプロダクトマネージャーがインフラ領域への投資判断をできるような仕組みを構築するというものです。
ソリューション検討
次に前述の課題を具体的にどうやって解決するかを考えていきます。解決したい課題の本質はあくまでも「負債が溜まらないような体制の確立」であるため、短期的な解決だけにならないように気をつける必要があります。
何度も議論を重ね、私のチームでは以下の4つを軸にソリューションを展開することにしました。
モダンなインフラ構成にリプレイス
従来のEC2を中心としたインフラで構成されていたアプリケーションの各種サブコンポーネントやデータパイプラインをできるだけフルマネージドなインフラサービスに移行することでメンテナンスコストの削減や高可用性の担保を目的とするものです。
メインで担当していたメンバーの退職やチーム体制の変化によって発生するコンポーネントの引き継ぎに発生するコストの増大や、開発・運用を行うための知識やノウハウが属人化している状態が長らく問題視されていたため、できるだけ自分たちで管理する領域を小さくしていくことでこれを解決しようとしました。
コード化された監視パッケージの提供
これまでサービスごとに個別、かつ無秩序に実装されてきた監視・アラートをコード化し、サービス横断で利用できるような形で提供します。
具体的にはDatadog MonitorをTerraformでコード化し、監視のテーマごとに1つのレポジトリに切り出して管理します。このレポジトリは複数のサービスで利用できるように適度に抽象化監視パッケージを提供します。
また、サービスに大きな影響があるようなエラーが発生した時にその原因を早く見つけ出すことができるように各種メトリクスを1つの画面にまとめたDatadog Dashboardも同様に1つのレポジトリに切り出します。
groovesが展開するサービスはいずれもWebサービス、かつ人材ドメインに特化したものであるため、見るべきメトリクスやアラートを上げるべきしきい値は共通しています。共通のパッケージとして提供するメリットが大きいことは明らかでした。
SLOの策定、エラーバジェットの運用開始
開発チームがインフラ領域の改善を継続的に行うためには、プロダクトマネージャーと開発者が共通の指標を元に開発リソースを投下すべきかどうかを判断できるようにする必要があると考えました。
SLOはまさにこのために機能します。
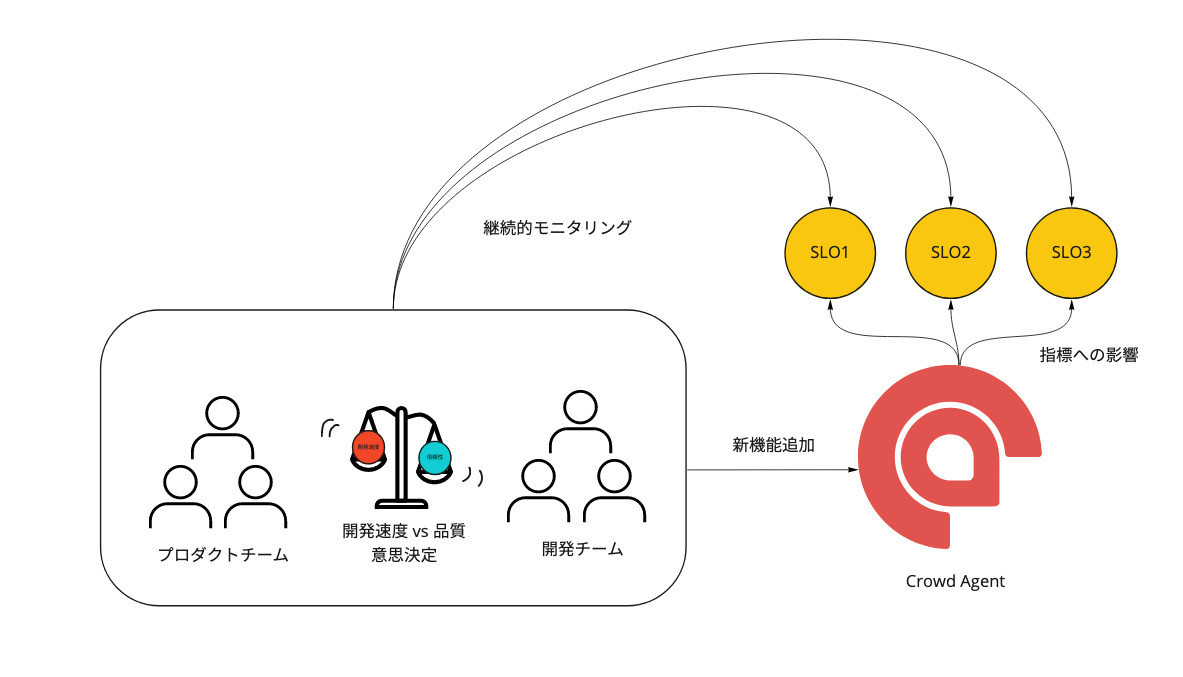
エラーが起こりづらいアーキテクチャへの作り変えや、コードレベルでのリファクタリング、パフォーマンス改善など、開発者が手を付けたくてもそのきっかけがなくて中々行動に移せない信頼性向上のための改善を行うための工数を確保するためには、SLOやエラーバジェットなどSREのプラクティスを導入すべきだと判断しました。
インフラ知識、トレーニングの提供
これはまさに専門性の高いチームが価値を発揮するソリューションです。
AWSやDatadogなど、各種インフラサービスの専門知識を豊富に備えたメンバーからアーキテクチャのコンサルティングを受けたり、ハンズオン形式のトレーニングを中心に開発者自身のインフラスキルを向上を図ります。
最終的には各開発チーム内で自然とインフラスキルの平滑化が進み、メンバー間のスキル差が小さくなることでコンテキストを共有し、品質の安定化や説明コストの最小化を狙っています。
説得のための材料集め
ここまで来れば新チームが行う活動が日々の業務レベルでかなり明確になってきています。自分の中では成果が出ることの確信が持ててきていますが、組織で働いている以上ステークホルダーの承認を得る必要があるでしょう。
多くの意思決定者が欲しい情報は、(1) どんな成果が出るか (2) それにはどのくらいのコストがかかるか ということだと思います。いわゆるコストパフォーマンスというやつですね。
今回の場合は得られる成果が主に信頼性向上ですので、過去発生した大きなエラーで損失した金額を計算して、どのくらい減少しそうか試算してみると良いでしょう。
また、開発チームがモダンなインフラサービスを活用できるようになることで実装工数が小さくなったり、メンテナンスコストの減少も見込まれます。
コストに関しては人件費とほとんど同義です。どのくらいの期間で上記成果を上げられるかをざっくりのタイムラインにまとめました。もちろん、タイムライン通りに計画が進まないリスクがあることや、タイムライン上の具体的なマイルストーンが変更されることも合わせて説明します。
私の場合、このエントリーに書いた情報を1つのドキュメントにまとめて「マスタープラン」として意思決定者に提出、説明することで承認をもらいました。
まとめ
専任のインフラチームを持たない組織では開発チームが継続的にインフラ領域の改善を行う難しく、それが故にいざとなると何から手を付けてよいか分からないことも多いのではないでしょうか。
私達は「クラウド推進室」という専門組織によって持続可能な方法で開発チーム自身が適切にインフラを管理できる状態をつくることが望ましいと考え、その実現に向けて活動しています。
余談になりますがクラウド推進室では課題選定から実装までの活動を非常にユニークなプロセスを使って行っています。詳しくは別のエントリーにまとめていますので、こちらもぜひ併せてご一読ください。
groovesでは開発エンジニアを筆頭に、多くのポジションで一緒に働く仲間を募集しています。リモートワーク制度、フレックス制度を採用しているので仕事とプライベートを両立した働き方が可能です。沖縄、北海道、長野など首都圏以外から働くメンバーも多数在籍しています。
開発チームに関しては2017年頃からフルリモートを前提とした組織体制を構築しているため、リモートならではの様々な課題に向き合い、乗り越えてきた歴史があります。リモートで働きたいけれど実際やってみるのはちょっと不安がある、開発以外の他のメンバーの理解が得られるか心配、自分がリモートで成果を出せるかイマイチ自信がない、という方こそぜひお気軽にエントリーしていただけると嬉しいです。